
いつもご覧下さりありがとうございます。
久しぶりのScanSnap自炊シリーズ、今回は名刺のデジタルデータ化をやってみました。
書籍の自炊に比べれば、さほど省スペース化に効果がある訳でもありませんが、検索はコンピュータの得意技。連絡先を探すのは割と便利になるかもしれません(…むしろ住所録データベースの作成と言うべきかもしれません)。
で、基本的にはScanSnapにバンドルされてるアプリを使うだけで簡単に出来るのですが…
並行して今回はPDFファイル形式での自炊もやってみました。
なんかこう、『ある特定のソフトでのみ使用する形式のファイル』が増えるのがヤだなー、という方は多少ご参考になるかと。ホラ、昔のデジカメでよくあったでしょ。同梱付属してきた安っぽい自社ソフトが使いにくくて、結局、Windowsのエクスプローラーで写真見た方が楽、みたいなアレ。PDFで保存しておけば、例えばPC買い替えたり、OSがバージョンアップ(Windows7もあと一年だし)したりしても、そのまま閲覧できますんでね。
ま、会社(ビジネスユース)と違って個人レベルではそれほどニーズも無いネタかと思います。
ですが、似たようなケース、例えば年賀状のデジタルデータ化とか、飲食店のレジで貰う電話番号カードなんかにも応用できそうです。あとは…嫁さんに内緒にしときたい、飲み屋のお姉たまの名刺とかも…ね(^^;)
ということで参考程度にどうぞ。
古い名刺フォルダーが出てきた
昨年来の身辺整理(あえて断捨離とは言いませぬw)もだいぶ佳境に入ってまいりました。
思い出の詰まったアレやらコレやら、ガンガン捨てまくってすっかり涙目の管理人でございます。尾崎豊風に言えば「むやみーに何もかも捨てちまーったけれど~♪」(涙)。
んで、割とたーっくさんあった蔵書もあらかた処分してしまい、最早、本棚も要らんな、というレベルですが…、

最後の最後で、書棚の隅から昔の名刺フォルダーが出てきたのですね。
まあ、すっかり忘れてたってことは、昨今利用してない=ハッキリ言って要らない=そのまま捨てちゃっても問題ない訳です。ですが、「そういや、ScanSnapに『名刺ファイリングOCR』なるソフトが付いてたな」と思い出し、興味本位で試しに弄ってみようか、と。
結論から言うと、
こりゃあ便利!! (゚∀゚)
もっと早く気づいておれば…、というか、まあ昔はこんな便利な機械が無かったからしょうがないけど。
手間=スキャンに伴う作業時間はそれほど掛かりません。
むしろやっかいなのはアナログの手作業、つまりフォルダーから一枚一枚、名刺を取り出すのが一番面倒くさかった(笑)。なので、既にドキュメントスキャナーを持ってる方は、四の五の言わずにサッサとやった方が良ろしいかと。マジでおすすめ。
ということで、以下、作業工程と、その過程で気付いたコトなどを備忘録的に残しておきますネ。
| ScanSnapって何じゃそれ?という方は、以前に投稿したこちらを御覧ください。 ⇒『レンタルもおすすめ♪ヤフオク購入のScanSnapS1500で文書電子化&自炊が爆速に!!』 応用編もどうぞ |
1.付属アプリ「名刺ファイリングOCR」での自炊は超簡単で便利
まずはScanSnapに付属の上記ソフト(アプリ)での自炊方法です。
「早よ、PDF化のやり方教えんかい、コラ!!」とお急ぎの方は読み飛ばしてくださいませませw
(PDFデータ化の詳細は下の方に後述しとります)
んで、ちょっとググるとたくさん出てくるのでご存知の方も多いかと思いますが、最近はあまたの名刺管理ソフトがあるようです。松重さんの「早く言ってよ~」のCMでおなじみのSansanのEightとかね、クラウド連携で管理できて便利な人気サービスも多いです。ですがまあ、スキャナーに最初から「タダ(無料)」で付いてるモノがあるのですから、わざわざ買う必要はありません。
そしてこの「名刺ファイリングOCR」も、数ある名刺管理ソフトの中でも比較的古株というか「老舗」のアプリだそうで、利用者の評判もナカナカとのこと。これを使わない手は無いでしょう。
スキャンする名刺の取り出しとScanSnap Managerの設定
まずは、フォルダーから名刺を一枚ずつ抜き取ります。

何が面倒って、この作業が一番メンドクサカッたw 引っ掛かってナカナカ出てこないんだもの。
この「紙名刺」フォルダーを実際に使ってた遠い昔、一応、カテゴリー別にページを分けて、それぞれにタグシールを貼ったりして分類しておりました。同級生、とか、取引先とか、異業種交流…みたいな感じ。つーことで、せっかくなので、ぐちゃぐちゃにならんよう、抜き出した名刺は元のカテゴリー毎にまとめて置いておきます。スキャンする際も、カテゴリー毎に作業を進めてゆくのが楽です。
続いてScanSnap Managerを起動し、設定画面へ参ります。
最初に、左上の「クイックメニューを使用する」のチェック(レ)を外します。
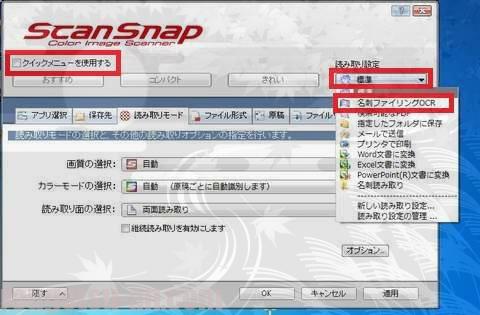
すると右上の「カスタマイズ」ボタンがアクセス出来るようになり、クリックするとプルダウンメニューがビロ~ンと出てきます。
で、上から二番目の「名刺ファイリングOCR」を選択。

設定は以上!! の超楽チン仕様です。
解像度やファイル形式その他細かな仕様は全て予め設定されている「オマカセ」であります。要するにオートマってことですね。読み取りモードは多少イジれるようですので、「完全にデフォルトのままじゃイヤん」という方はご自身で納得ゆくまでイジってみてくだされ。
念の為一応、「読み取りモード」タブの「継続読み取りを有効にする」のチェック(レ)が入ってることだけは確認しておきましょう。というのも、名刺は厚さがソコソコありますので、イッキに全部は入らないのですね。一回で20-30枚位が限度ですので、都度、フィーダーに補充する感じになります。
ScanSnapでの取り込みとOCRデータの修正
あとはScanSnapに名刺を入れてスタートボタンを押すだけ。
カテゴリー分けしておいた「一山」ごとに、スキャナーに流してゆきます。

いつものようにガーッと一瞬で読み込んでくれます。特に注意点はありませんが、
- 今回は横長の方向(長辺を下)で流してみましたが、この方が多少速い&安定していたようです。
- 重送や原稿ジャムは一回も発生しませんでした。
という感じで、ほぼノートラブルであっという間に取り込み完了。一つのカテゴリーの名刺が全枚数スキャンできたら、一旦終了します。すると…
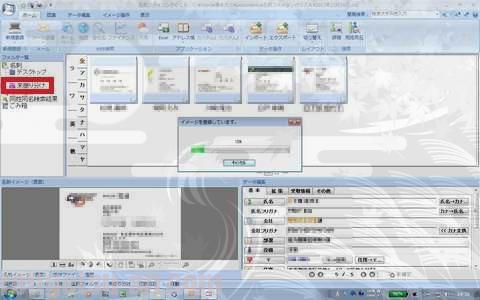
自動的に「名刺ファイリングOCR」が起動し、イメージを変換して個別ファイルにしてくれます。
おそらく、両面をひとつのデータとして認識、ファイル作成し、自動で向き補正をして…とやっているのでしょう。さらに、OCR処理(光学的文字認識)も行っているようで、情報としての「住所録データ」が自動で出来上がってゆきます。
ここまで全自動ですので見てるだけ。鬼のように楽ですw
ただね、OCRがあんまり賢くないようなんですよね~。
文字化けと言うか、誤植というか、住所録データはそこらじゅう間違いだらけ(笑)なのであります。会社名を名前として認識しちゃってたり、名前が職位になってたり(笑)。ですが修正は比較的簡単で、項目別(名前、住所、会社名など)にピンポイントで再OCRをかけるか、もしくは直接手入力します。
ま、住所録としてガッツリ使用するには、手直しが必須、と思っといた方が良さそうです。
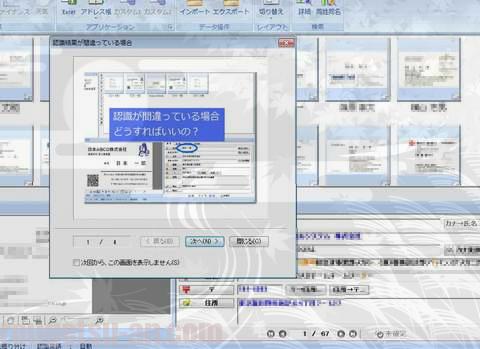
スキャン終了後、毎回修正作業のガイドのポップアップが出るので、手直しのやり方を忘れてしまっても安心♪
この修正作業はそこそこメンドーっちゃ面倒。
名刺交換の度に毎回一枚分スキャンするだけならさほどでもないけど、フォルダー一冊まとめて…となると、かなりの時間が掛かると考えた方が良いですね。今回、興味本位でこの作業を試みた管理人は当然、全て放棄であります。一切やってないw
まあ、うちの子は古い機種(ScanSnap S1500は2009年のモデル)なのである程度はしょうがないかなぁ。最新のScanSnapに同梱されてる最新バージョンの「名刺ファイリング~」だと、OCRがもう少し賢いのかもしれませんね。
カテゴリー別にスキャンして、フォルダー分けすると整理しやすい
処理が終わると、出来上がったデータは一旦、『未振り分け』というフォルダーに格納されます。
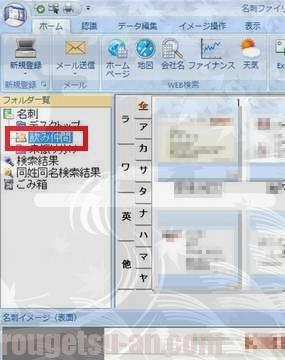
なので、↑こんな風(『飲み仲間』とか)に、カテゴリーのフォルダーを作ってやって、そこにドラッグ&ドロップで移動させてあげます。これを一回スキャンする毎にやっとかないと、あとで混乱します。ぐちゃぐちゃになってからでは遅いので、忘れずにやっときましょう。
で、同じ要領で残りの名刺もカテゴリー毎にスキャナーにかけてゆきます。
すると、最終的にはこんなイメージになりますね。
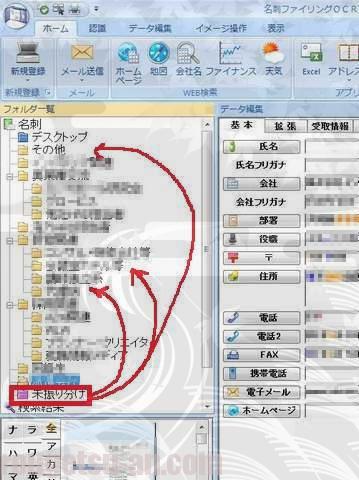
フォルダーは階層化出来ますので、カテゴリーが多い場合は、あとから大分類、中分類を作って整理してやれば簡単です。また、しばらくしてから分類を見直すして入れ替えたりするコトも容易に出来ます。この辺は紙の実物の管理よりも圧倒的に優位ですね。
尚、細分化してカテゴライズしたとしても、全データをまとめて「あいうえお順」に閲覧することも可能ですのでご安心を。
補足:家庭用プリンタ付属のフラットベッドスキャナーでも使える?
最後に補足です。せっかくなので少しだけ触れときます。
今回は試してないのですが、この「名刺ファイリングOCR」というソフト、フラットベッドスキャナーでも一応、使えるらしいのですね。今や家庭用プリンターも大概複合機になってますのでね、天板開けるとガラス面になってるアレです。
ScanSnapに比較すると、当然時間は掛かるんだろうけど、それでも「一枚ずつ」というコトは無いはず。複数枚同時読み込みする機能があれば思ったより速いんじゃないかなぁ。表裏をどうやって紐付けるのかがよく分かりませんけどね。
ドキュメントスキャナーは高価ですからね。一応、「ソフト」だけあれば出来ないことはないようです。ご参考に。敢えて名刺の為だけに買うのもなぁ、という方は一考の余地ありかと。
2.PDF形式のファイルとしてデジタルデータ化
続いてPDFファイルでの自炊方法についても見て参りましょう。
今回はトライアルで、ということもあり、同時にこちらの方式もやってみました。
ま、実用上は片方だけで十分っちゃ十分なのですが、後日試そうと思っても、一旦シュレッダーにかけちゃった名刺は二度と帰ってきません。いくらScanSnapでも捨てた名刺は読み込めないのであります。我ながらナイーブなA型w
PDFかJPEGか?ありふれたファイル形式で保存するメリットとデメリット
せっかく便利な名刺管理ソフトが付属しているのに、敢えてPDFで…と思うのもごもっとも。
ですがまあ、こういう「極めて汎用性・浸透度の高いファイル形式」で保存しておくのも一理あります。
結局ですね、名刺管理ソフトで作成したデータ(ファイル)ってのは、原則としてそのソフトが無いと読めない訳ですね(まあ、他のファイル形式にエクスポートする方法はあるけど)。
将来、パソコンやスキャナーを買い替えたり、Windows10にしたり、とかね、「名刺ファイリングOCR」がサポート終了になっちゃたり、だけど会社辞めちゃったから新た貰う名刺は無い=スキャンするニーズは無いし…とかまあ、そういうことはよくあります。その度に、わざわざ無用なソフトを買い直さんでも、PDFならいつでもどこでも閲覧できると。
一時マイクロソフト肝入りだったXPSは既に事実上絶滅し、世界中でAcrobatのPDFが電子文書のデファクトスタンダードとなっておりますので、今後十数年はPDF形式が世の中から消える可能性は低いでしょうしね。
視覚的に見易いJPEGに対し、管理と検索が楽なPDF
ただね、もっと簡単に、JPEGで保存しておく、という方法もあるかなぁ、とも考えたのですが…
Windowsのエクスプローラーだと、JPEG画像ファイルはサムネイル表示してくれるので、フォルダーを開くだけで、視覚的に見易いってのは確かにあります。ですが、名刺ってのは表裏の二面ありますので、スキャンする度にいちいち連結しとかないと、一枚の名刺がファイル2個になっちゃうんですよね。
この辺は、2ページを1ファイルで保存できる、PDFの方が整理は楽かなぁと。
あとは、検索ですね。
実際に使う時、つまり名刺を探す際は、ページを捲って目で探すよりも、検索から引っ張り出せる方が圧倒的に楽です。となると、Acrobatさえあれば簡単にOCR加工できるPDFの方が優位かと。
JPEGで検索利用を想定すると、名刺一枚ずつ、「ファイル名を『氏名』にする」など、手作業が多く発生しそうです。ま、PDFでも結局、ファイル名は「IMG001、IMG002…」みたいになっちゃって味気ないんだけど、一応、フォルダーから検索はできるし。
どちらも帯に短しタスキに…というか、一長一短ですが、今回はPDFにしてみました。この辺は個人のお好みで利便性の高そうな方法を選択すればよいのかな?と思います。
ScanSnap Managerにてユーザー設定を作成・保存しておくと便利
では実作業。まずはScanSnap Managerの設定画面です。
先程と同じく、左上の「クイックメニューを使用する」のチェック(レ)を外し、右上のプルダウンメニューから、「新しい読み取り設定…」をチョイス。
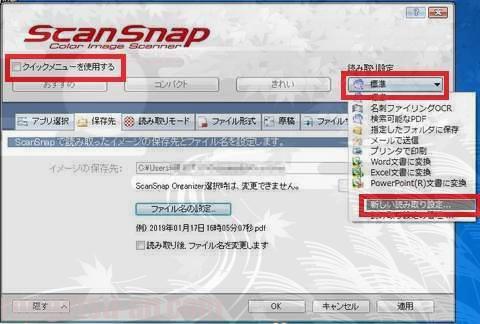
何をするかというと、今回、名刺をPDF化する仕様を、ユーザー設定として保存しておくのであります。
これをやっとくと、後日、同じような作業、つまりもう一回別の名刺読み取りをする時に便利なのよね。次回は、このユーザー設定を選択するだけで全く同じ仕様・設定になりますので、いちいち「モードはこれで…、ファイル形式は…、白紙は…」とかやらないで済むのであります。
んで、下のようなダイヤログボックスが出てきます。
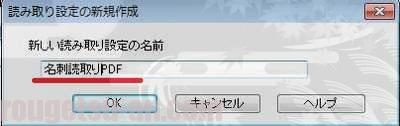
ここで、テキトーに好きな「ユーザー設定名」を決めて、入力します。するとScanSnap Managerの右上に、今作成した「ユーザー設定名」が出てきます(↓下の写真参照)。
アプリ選択
続いて読み取りの細かな仕様をセットしてゆきます。
まずは一番左のタブ「アプリ選択」

ここは特に不要ですので、「アプリケーションを選択しません(ファイル保存のみ)」を選択。
保存先
右隣のタブ「保存先」です。
保存先は自分で好きな場所(デスクトップとかマイドキュメントとか)を決めましょう。
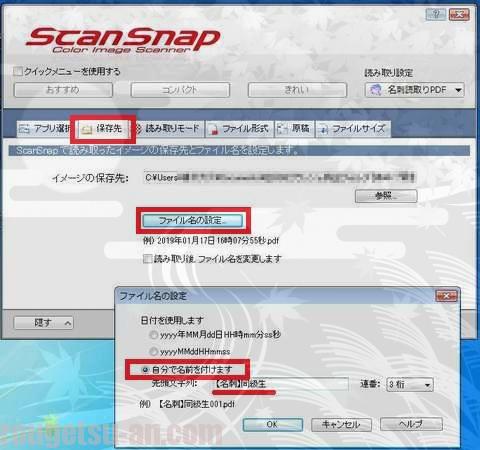
割と大事なのが、真ん中の「ファイル名の設定」。
ここをデフォルトのままにしとくと、やたらと長い『年月日時間分秒』形式のファイル名が量産されてしまい、見た目も汚らしくなってしまいますw
ということで、「自分で名前を付けます」を選択し、何らかのパターンを設定するのが良いでしょう。
管理人は今回「【名刺】●●●」のように、カテゴリー毎に「●●●」だけ変えるパターンでやってみました。一つのカテゴリーの名刺をスキャンする度に、都度、ここの設定を変更することになりますが、それほど面倒でもなかったかな。
●●●の部分、具体的には、
「【名刺】サークル001、【名刺】サークル002、【名刺】サークル003、…」
「【名刺】自治会001、【名刺】自治会002、【名刺】自治会003、…」
「【名刺】ゼミ001、【名刺】ゼミ002、【名刺】ゼミ003、…」
…みたいなイメージでファイルが出来上がって来ることになります。
まあお好みでどうぞ。
読取りモード
続いて右隣、「読み取りモード」です。
画質は「スーパーファイン」、カラーモードは「カラー」、読み取り面の選択は「両面読み取り」ですね。
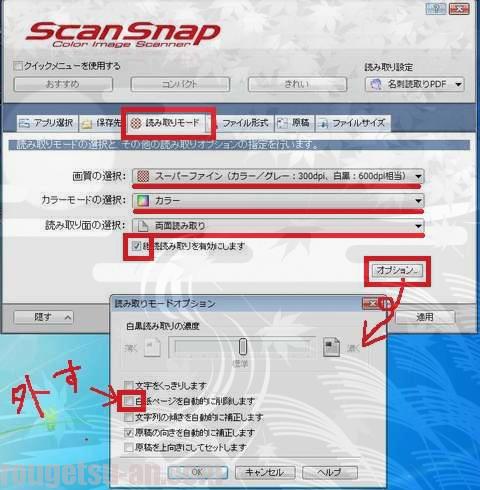
で、上の方でも触れましたが、名刺の『紙の厚さ』の関係上、一度に20枚程度しか読み込めませんので、「継続読み取りを有効にします」のチェック(レ)を入れておきます。さらに、右下の「オプション」を開き、「白紙ページを自動的に削除します」のチェック(レ)を外します。たまーに裏が無地(何も書いてない真っ白)の名刺が混ざってたりするので。
ファイル形式
続いて右隣の「ファイル形式」。ここはPDFですね。
重要なのが右下の「オプション」。ページ分割は、「設定ページごとにPDFファイルを作ります」を選び、数字の「2」を入力します。要するに、表裏両面2ページで1ファイルとする為であります。
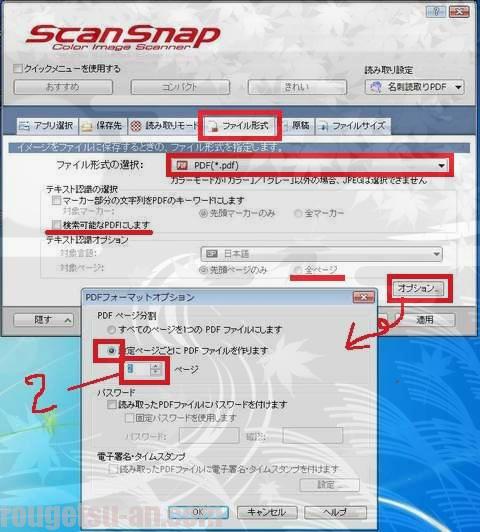
尚、中段にある、「テキスト認識の選択」について。
ここで「検索可能なPDFにします」のところにチェック(レ)を入れる方法もアリです。このチェックを入れておくと、スキャン⇒PDFファイルを作成する時点で自動的にOCR処理もやってくれる仕様です。
今回、管理人は、ここのチェックを入れておりません。
代わりに、『全部スキャンが終わった後、あとからAcrobatでOCR処理する』方法を選択しました。理由は、①どうもAcrobatのOCRの方が賢い「らしい」②AcrobatでOCR化すると、ファイルサイズが小さく(圧縮?)なる、の2点。
ですがAdobe Acrobat(無料のReaderではありません)を持っていない方は、この方法は選べません。
なので、必然的にPDFファイル化と同時にOCR処理する方法がベターでしょう。その際は「検索可能な…」にチェック(レ)を入れると同時に、右下の「全ページ」を選択しておくこともお忘れなく。
設定は以上です。
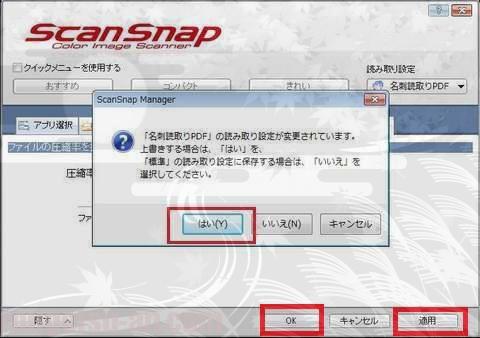
「適用」⇒「OK」とすると、窓が開くので、「はい」を選んで、今、設定した内容を保存します。
ScanSnapで読み取り(PDFファイル化)が成功したら、名刺はシュレッダー廃棄
んで、上記で作成した設定(ユーザー設定)の状態で、ScanSnapにて名刺の読み取りを進めてゆきます(カテゴリー毎にファイル名の設定を変更してスキャンしました)。すると…
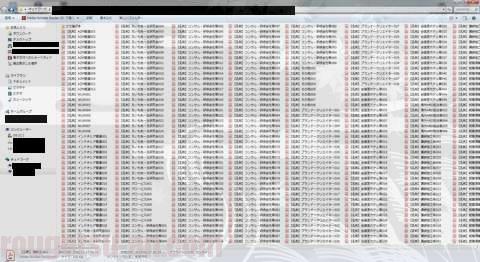
全部終わると、こんな感じで大量のPDFでファイルがw
…ということで、PDFファイルの作成も完了。

お役御免の古い名刺さんは、全てシュレッダーにお逝きになっていただきました。合掌。
Adobe Acrobatを使ったOCR処理
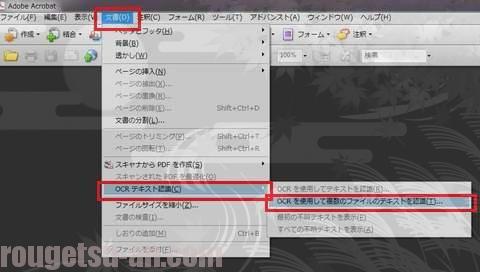
では後回しにしておいた、OCR処理を行います。
若干古い(^^;)我が家のAcrobatさんに起動していただき、メニューから⇒「文書」⇒「OCRテキスト認識」⇒「OCRを使用して複数のファイルのテキストを認識」と進みます。
開いた窓の左上、「ファイルを追加」をクリックし、先程作成したPDFファイルを全てここで指定します。
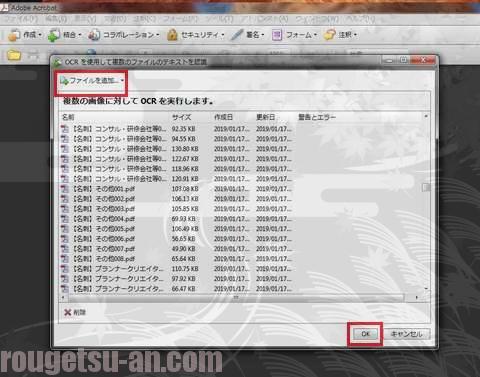
「OK」を押すと、続いて、OCR処理の設定です。
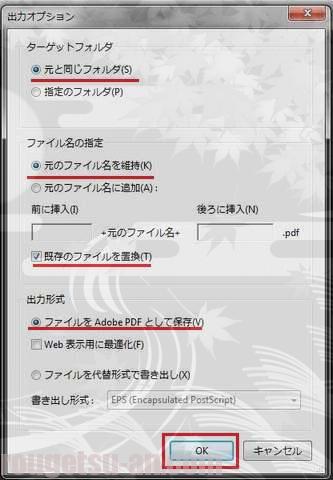
ここは好き好きですが、「元のファイル名を維持」「既存のファイルを置換」「…PDFで保存」という、デフォルトのまま「OK」。万一の失敗が怖い場合は、置換で無いほうが良いのかもしれません。
続いてテキスト認識の設定です。こっちはやや重要。
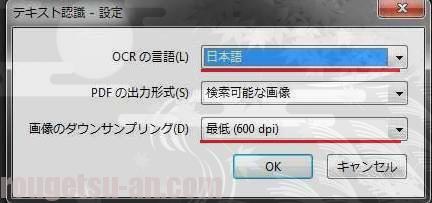
デフォルトのままですが、「日本語」と、最上位の画質「最低(600dpi)」になってることを確認。
んで、OCR処理をGO!! ですが…
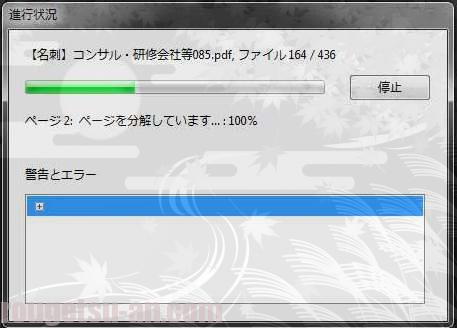
ファイル数が大量過ぎて、さすがに時間が掛かる掛かる(^^;)
一回、途中でエラーが出てやり直しになっちゃいました。何度やってもダメな場合は複数回に小分けした方が良いかもしれません。
15分位掛かって全ファイルのOCR処理が完了。
試しに検索してみたら…予想以上に速い!!
では、試しに検索を掛けてみましょう。先程の大量のPDFファイルが入ってるフォルダーを開き、エクスプローラーの検索窓(右上)に「山田」と入力すると…
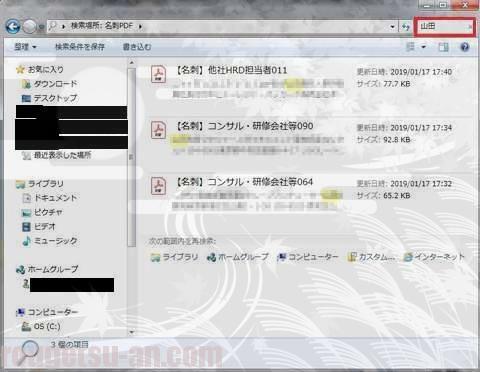
「山田さん」を含む三件のファイルがサクッと出てきました。
今回作成したPDFファイル、そのファイル名自体は氏名ではありません(「【名刺】同級生001」とかになってる)ので、中身=PDFファイル内の文字データを検索ヒットしているハズですが…、いやいや全然速いし、これは十分使える。イケるんじゃね?
別の検索方法:閲覧用として一つのPDFファイルに結合してみた
続いて、Acrobat Readerから検索する方法も試してみましょう。
全検索を掛ける為に、一旦、「スキャンした全てのPDFファイルを、ひとつの『閲覧用のPDFファイル』に結合する」作業を行います。
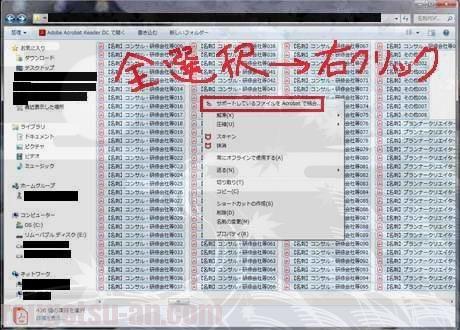
当然ですが、この作業もAdobe Acrobat(無料のReaderじゃないヤツ)を持っていないと出来ませんのでご注意を。Acrobatがインストールされている方は、先程のフォルダー内の全PDFファイルを選択し、右クリック⇒「…Acrobatで結合」をクリック。
開いた窓で、ページの順番を入れ替えることが出来ますが、今回は不要ですのでそのまま。
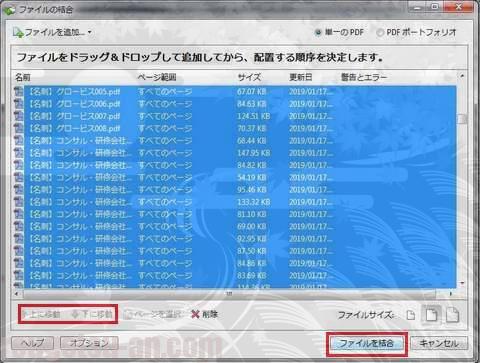
問題がなければそのまま右下の「ファイルを結合」をクリック。
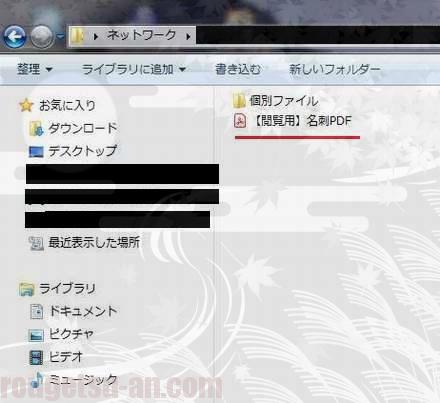
で、数分後、全ファイルを結合したこちらのファイルが出来ました。この一つのPDFファイルに数百枚の名刺が全て入っています。ファイル名は便宜上、「閲覧用…」としておきました。
では、Acrobat Readerで開いてみましょう。
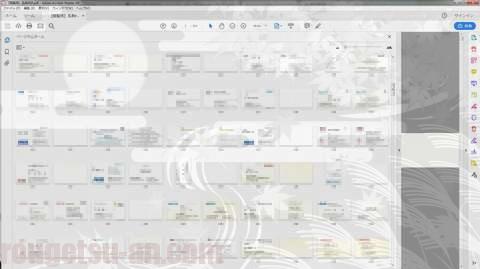
こんな感じになりますね。一人分が表裏で2ページずつですので、所々に無地(真っ白)が混じっています。
検索はこちらの方法の方が速いかと思ったが…?
で、Acrobat上で検索、すなわち「Ctrl+f」で検索窓を開き、「山田」と入力、検索を掛けてみたのですが…
遅い!!
全然ダメですね。以前にやった、英和辞典を自炊して自作電子辞書を作った時みたい…というと言い過ぎだけど、かな~りレスポンスが悪いです。数秒~十数秒は掛かるイメージ。
うーん、使えないコトは無いけど…
先にやった、ファイルは別々(名刺一枚でPDFファイル1個)にしておいて、フォルダーの検索窓から検索する方が圧倒的に速いですね。
逆の結果になると思ってたんだけどな~。なんでだろ?
まとめ
ということで、一応2パターン、名刺管理ソフトとPDF、両方やってみたけど…
うーん、感覚的には「名刺ファイリングOCR」の方が断然楽だったかなぁ。
スキャンする作業もかなり楽だったし、データベース化してくれるのは後々のことを考えると、業務効率的にもかなり助かるのではないでしょうかね。ガチで使うには若干データ補正の手間が掛かりますが、一から住所録を作成するよりは遥かに楽なはず。
個人的には、こういったアプリ限定のファイル形式ってのはあまり好きくないのですが…
まあこのソフトに関してはソコソコの認知度・浸透度・シェアがあるようですので(ハードであるScanSnap自体の強みの裏返しでしょう)、そんなに悪い選択肢では無いかなと思います。
個人的には、「名刺ファイリングOCR」のデータをPDF形式でエクスポート出来る機能があればベストなんですけどね。ちょっと分かりませんでした。
…ま、そういった事も含めて、私も富士通の営業マンじゃありませんので(笑)、この機械・ソフトの全機能を把握しとる訳でもございません。「アホか、もっと便利なこんなコマンドがあるで~」ということも有るかと思います。そこのトコは勘弁してね。
以上、あくまで素人の使用感として、ご参考にして頂ければ幸いです。
本日も最後までお付き合いくださりありがとうございました。
富士通公式通販(WEB MART)のスキャンスナップのページはこちら
⇒『富士通パソコン通販 カラーイメージスキャナScanSnap 』
昨秋、6年ぶり?のモデルチェンジで新製品が登場したようです。

値崩れする型落ちモデルを狙うチャンスかも?
こちらもどうぞ♪
⇒『OCR一発検索の自作電子辞書?英和辞典の自炊やってみた』
⇒『卒業アルバム捨てる前に自炊電子データ化してみた』
⇒『レンタルもおすすめ♪ヤフオク購入のScanSnapS1500で文書電子化&自炊が爆速に!!』 オススメ
⇒『年賀状を捨てる!!スキャン⇒パソコンでデジタルデータ保存』
⇒『安くて在庫豊富なネット通販「駿河屋」で古本購入してみた』
⇒『証券会社の書類をシュレッダーで大量処分』
⇒『故障シュレッダー試しに分解してみた&コクヨSilent-Duoが予想外に凄かった件』 オススメ
⇒『プリンターインク代を限りなくタダにする方法』
⇒『ワンクリック??で簡単♪AcrobatでXPS⇒PDF電子文書ファイル変換』
⇒『Word無料テンプレートで簡単 プリンターで印刷する喪中はがき』




コメント