
いつもご覧くださりありがとうございます。
「実験君」のネタ記事です。
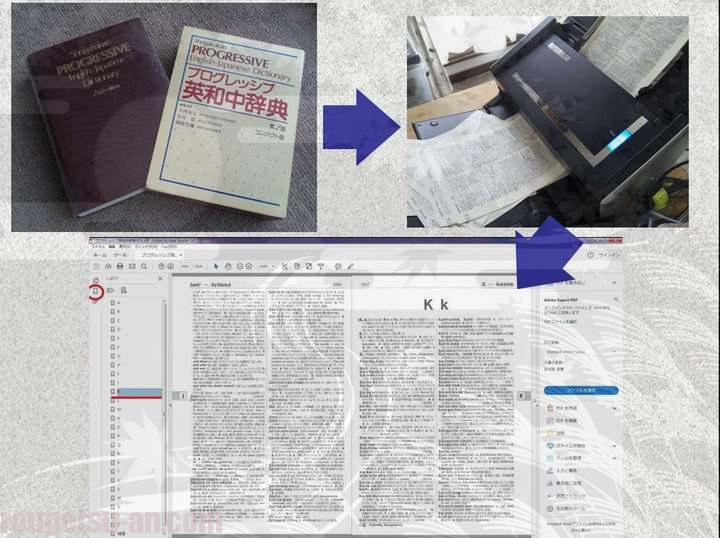
昨秋購入した富士通ドキュメントスキャナーScanSnap(詳しくはこちら⇒『ヤフオク購入のScanSnapS1500で文書電子化&自炊が爆速!!』)で、英語辞書の『自炊』をやってみました。世の中には既に電子辞書ってモンがフツーに存在してますけどね、考えてみりゃ、検索ってのはコンピュータが一番得意な技であります。出来上がったPDFファイルをOCR化できれば全文検索できるはずだし…との思惑でございます。果たして…(^^)
ま、ネタとは言っても、一応、『自炊』の手順としては通常とほぼ同様、というかむしろ普通の本・書籍の方がはるかに簡単です。一通り、自炊作業のやり方・方法も分かるように、多めに写真を入れておきました。なので、これから蔵書の整理整頓を考えている方には、「自炊作業自体」の参考にもなるかと思います。
結論を先にを言っちゃうと…、
決して失敗ではないけど、正直言って実用性はうーむ…(苦笑)、という結構ビミョーというか?(ハテナ)マークな結果でございましたw
まあ就寝前に布団で暖まりながらフフフとほくそ笑んでいただければ幸いです。あくまで興味本位でご覧ください。
ではどうぞ。
コトのいきさつ
ここのところ、アレやコレやの投稿で度々触れておりますので、ご存知の方も多いかと思います。一昨年来、押入れ整理であらゆるモノをドッカンドッカン捨てるという状況が続いておりますが、とりわけ多いのが紙と本。
ま、そのままバッサバッサと捨てちゃっても良いのですけどね、なんかこう、根がナイーブというか未練がましい性分なもので。で、せっかくドキュメントスキャナーを導入しましたので、思い出や愛着のある書籍とか写真、年賀状とかの類は、なるべくスキャンしてから捨てるようにしておるのでございます。きっと後で読みたくなることも…あるよね、あると思いたい(^^;)

で、まあ文庫本から、新書、学術書、教科書、ビジネス本、ガイドブック、雑誌、漫画、コミック単行本等々、いろいろな書籍を自炊しては捨て、を繰り返し、ダンボールの山も徐々に減ってきたのですが…。先日、奥の箱から辞書が7冊も出てきたのであります。ロクに使いもせんのによくまあこんなに何冊も買って…アホですなw
これは絶対使わん、イランよな~、とも思ったのですが…
ホラ、辞書ってやたらとページ数が多くて分厚いでしょ。人類の英知が詰まってる感じがするしね、問答無用で捨てちゃうのも、なんつーかこう心が痛むというか。免罪符って訳でもないけど、言い訳の儀式みたいなモンであります。
そして、若干実験君なノリもありつつ。
使う予定は無さそうだけど、万が一にも「超便利」な電子辞書ができちゃったりして…という期待はあまりないけど、ま、試しにやってみっかと。結局のところ何とな~く、という理由なんですけどね(^^;)
ということで能書きはホドホドにして、実際の作業に参りましょう。
まずは辞書(本)を裁断してバラバラにする
高校で使ってた(?)プログレッシブ英和中辞典
今回生贄になっていただくのはこちら、小学館のプログレッシブ英和中辞典です。高坊の頃に使ってたヤツかな?

現在と違って電子辞書が無かった時代、当時はこんなモノをみんな買わされたものです。今はどうなってるんでしょうか。ただまあ電卓がある時代にソロバン買うようなモンだよね。
横から見ると結構厚みがあります。

30年以上前のモノですが、綺麗そのもの。
経年劣化云々の前に、最初から、あまり使用した痕跡もないという。こんな分厚い辞書、結局大して使わないんだよね。持ち運ぶのは重いし、時間というリソースが限られている現代人にとっては、一々辞書引いてられる程、暇じゃーないのであります。だよね?
32ページずつ手で引っぺがしてゆく
では辞書をバラバラにしてゆきましょう。
まずはビニールの装丁というか表紙(正式な呼称は何て言うんだろ?)を引っぺがしてゆきます。

表紙をめくった裏側のページ、糊でガッチリ貼っつけてありますのでこれは剥がれません。なもんで、真ん中をカッターで切ってしまいます。裏表紙も同様に。
そうすると…

このように分離できました。
で、『ビニールの表紙側』は一旦置いといて、まずは『中身』の方に着手いたします。テキトーなページのカタマリごとにビリビリ破ってゆきます。

後ほどカッターで裁断する時に切りやすい厚さならOK。まあ文庫本や単行本などだと25ページ位でビリビリ破ることが多いです。辞書は紙が極薄いですのでどうなるか…
やっぱりページが多いため(2000ページ以上!!)、なかなか進みません。普通の本の10冊分相当ですからね~(汗)。

実際、今回辞書をバラしてみて初めて知ったこと。
この辞書は32ページ(16枚と言うべjきか、8枚を折った状態と言うべきか)ごとに「糸で」綴じてあり、その32ページの小ロット70個近くを並べて、最後に糊で背表紙に貼っ付けてありました。普通の本だと全ページがダイレクトに背表紙に糊付けだけなんですけどね、やっぱり辞書はページ数が膨大だからなのでしょうか。
作業的には糸が引っ掛かってやりにくい反面、ロットごとに、つまり正確に32ページずつバラせば、枚数が同じなので、楽っちゃ楽であります。10分程格闘した結果、出来上がったのがこちら。

32ページの小ロットが恐らく70個近くあるハズ。こりゃ先が思いやられますな(^^;)
サイズを揃え、カッターで裁断する
ではカットしてゆきます。
前回も出てきましたが、うちのはこういう上から『刃』を振り下ろすカッター。これもまた年代モノです。
綴じてある箇所(要するに折目の端っこ)から大体5mm位のところをカットします。あんまり端っこギリギリだと糊でくっついたまま重送となる頻度が増えますので、ある程度は内側をカットします。漫画・コミックのように見開きのコマが多い書籍の場合はギリギリを攻めたいところですが、幸い辞書にはそういうビジュアリーなページは皆無。

ちょっと見にくいのですが、赤線のところにモノサシのような透明ガイドがあります。
裁断する位置を決めたら、ガイドをネジで固定してしまいます。すると、以後、全てのページが同じサイズで裁断できるという地味にナイスな機能であります。
では…、ゆっくりとザクザク裁断して参ります。

慌ててやると、順番がおかしくなったり、途中でページが表裏逆(昇順⇔降順)になっちゃったりするのです。なんせカットする量が多いしね。ページ番号を確認しつつ、ちゃんと順番になっているか整理整頓して並べておきます。

面倒でもこういう途中のプロセスを丁寧にやっとくのが肝心です。テキトーにやってると、後で痛い目に逢います(経験者)w
裁断行程も10分ほど格闘した結果、完成したのがこちら。

ページが多い分、切り取った『ミミ』の部分も大量です(笑)。
このままだと、ハミ出た糊で癒着しているページが稀にあります。また、そうではなくとも裁断時のカッターの圧力で隣近所仲良しになってるページが結構あったりします。なので一通り、捩って、「くっ付いてる箇所」が無いかをチェックします。

最近はあまりやらないようですけど、銀行員がお札を数える時の「アノ」要領であります。
隣近所で仲良しになってるページが「ペリペリ~」と剥がれてくれます。糊で完全に接着されちゃってるページもたまに出てきますので、ひとつひとつ丁寧に手で分離してゆきます。この作業も2000ページあるので大変ですが、これも重送やジャム(紙詰まり)の原因になりますので、必ずやっとかないと後で痛い目に逢いますw
ここまでシッカリ下ごしらえができたら、いよいよScanSnapの出番。一番楽しいスキャンの行程であります。ですが…果たして?
ScanSnapでスキャン作業
スキャナーの電源を投入し、原稿をセット
ScanSnapの蓋をオープンすると電源が入ります。USBケーブルコネクターをPCに接続して準備OK。フィーダーに原稿をセットしてみます。

辞書の特性上、紙が薄い為ですが、フィーダーにかなり大量にセットできます。
150ページ(75枚)くらいは余裕です。漫画単行本なんかだと紙が割りと厚いので80ページくらいがイッパイイッパイですからね。尚、最終的にいろいろやってみて、一番安定してたのは100-120ページ(50-60枚)程度が良好のようでした。一回で100ページ捌ければ、20回で一冊分完了する目論見です。ですがこの『紙の薄さ』が後々悪夢を呼ぶことに…詳しくは後述(^^;)
尚、写真のスキャナー、我が家モデルはやや古い型落ちの「S1500」ですが、こちら(↓)が富士通が誇る名機、最新現行機種のScanSnap iX500 であります。興味の有る方はどうぞ。

結構お高いので二の足を踏む方も多いかと思います。
ですがこんな便利な物も無いって位、驚愕の高性能オススメツール。ヤフオク他で安い中古品をゲットしたり、一時的な利用で済みそうな方はレンタルを利用するという方法もアリです。
参考までに⇒『いろいろレンタル-DMM.com』
スキャンモードの詳細設定
スキャンモードの詳細設定も触れておきましょう。この辺は個人によって好みの問題もありますので、参考程度にどうぞ。
まずは『読み取りモード』タブから。
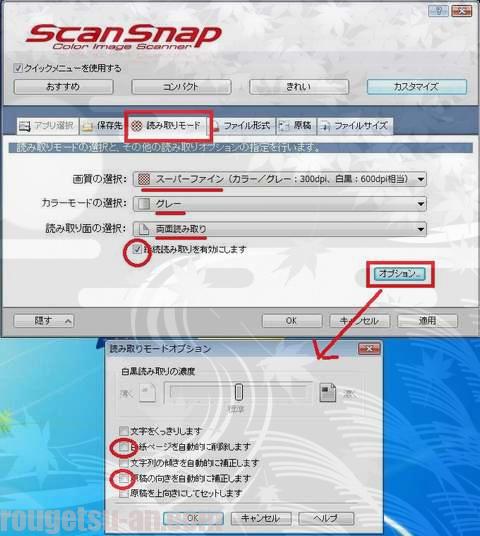
画質は基本的に常時『スーパーファイン』でやってますので今回もそのまま。
カラーは『白黒』の方がデータ量は圧縮できる筈ですが、今回は『グレー』にしました。理由は、辞書の所々に挿絵というかイラストが結構あったんですよね。白黒だと多分潰れちゃうハズ。一般的にテキスト文字ばかりの文庫本などは白黒、挿絵が多ければグレー、漫画・コミックはグレー一拓、という方が多いようです。余談ですが、日焼けの古本でもグレースキャンだと新品のように見えますw
その他細かい点。
書籍=両面印刷ですので当然『両面読み取り』です。
また、イッキで2000ページ分の原稿をフィーダーに載せてスキャンできませんので、『継続読み取りを有効にする』にもチェックを入れておきます。途中で継ぎ足し継ぎ足し、の作業となりますね。
オプションでは『白紙ページの自動削除』『向き自動補正』のチェックを外しておきます。実際、途中に白紙ページがあるので勝手に削除されちゃうとページがズレちゃう為、そして向きの補正は後ほどAdobe AcrobatでOCR処理する際に併せてやってくれるので問題なし。
続いて『ファイル形式』タブです。

JPEGではなくPDFで出力します。後で表紙などを結合する時(詳しくは後述)に、PDFの方がファイルが少なくて楽だからです。もしJPEGで出力すると2000ページ=2000個のファイルが出来ちゃいますのでね、一体どうなることやら。怖いモノ見たさで試してみたい気はしますが(^^;)
最後に『原稿』タブもチェック。
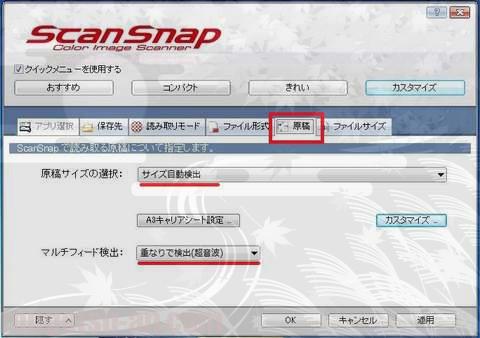
ま、弄るところはないですけどね、ちゃんと『サイズ自動検出』『超音波重送検出』が選択されていればOK。
ということで、ここまで設定が完了すれば準備OK。それではスキャンを開始しましょう♪
実際にスキャン作業開始!! …が、トラブル頻発???
では原稿をセットしてGoooooooooooooooo!! 一番楽しいスキャンのお時間です。

例によって超高速でガーっと読み込んでくれます。今日も頼もしいわ~。あっという間に積み上がるスキャン済み原稿の山。ですが…そんなパラダイス気分も長くは続きませんでした(T_T)
恐るべし!! 重送エラー地獄
開始して僅か、50ページ読んだ辺りで発生しました。
『重なりを検出しました』の悲しいお知らせ。オイオイまだ始まったばかりやで~。しつこいようですが、何しろ2000ページ以上もあるのです。先が思いやられます。
ま、やったことがある人は分かると思いますが、こんな画面が出てきますね。
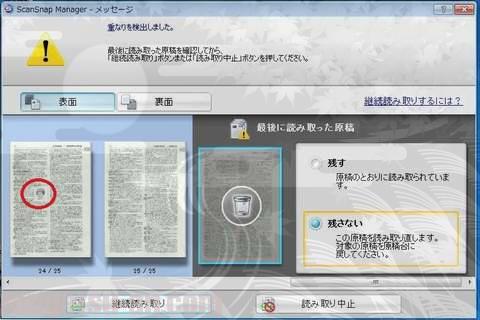
で、この画面と現物の原稿とを見比べてエラー箇所を確認することになるのですが…、
この非常に優秀なScanSnapの数少ない残念な点が、この重送エラー画面を拡大出来ないコト。『どのページまでOK』で『どのページがNGなのか』が分かりにくいのであります。色付きの旅行ガイドとか絵ばっかりの漫画etc.だと、各ページのデザインが全然異なるのですぐ分かるんですけどね。文字ばっかりの本だとどのページも全部同じに見えるというね。何しろ今回は辞書だし。

で、助けになったのが、辞書の所々に記載されてる挿絵というかイラスト。これが目印になりました。「このページはOKやからそこから●●ページ目が重送で、そこからやり直し…」とエラー箇所を特定するのに役立ちました。正直、コレ無かったら結構キツかった。
しかしこの後もエラーが頻発。
多分後から馴らすとアベレージ50ページに一回くらいは重送エラーが発生したと思います。辞書一冊スキャン終了するまで、恐らく合計で30回以上かな。フィーダーにセットする一回分の100-120ページがノーエラーで全部捌けることは数回しかなかったはず。
この機械、実際、かなり優秀で、超音波を駆使して重送をほぼ100%確実に感知してくれるのです。フィードも結構高精度で通常は重送エラー自体もそんなに多くないのですけどねえ。10月のScanSnap導入以来、ソコソコの数の本を自炊しましたが、こんなコトは初めてです。辞書、というかあの薄い紙、恐るべし。
原稿ジャム(紙詰まり)はほとんど無かった
対照的に原稿ジャムの発生は、今回は一回だけでした。こういうのも珍しい。
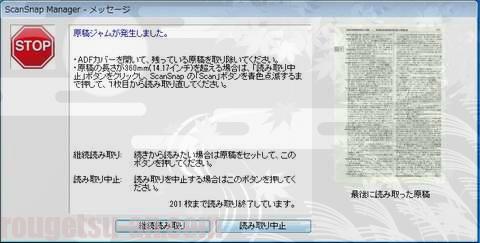
修羅場にならないよう、事前に念入りにチェックしたってのもありますが、各ページの最小単位が『直接糊で綴じてない(糸で綴じてある)』せいかもしれません。重送地獄でジャムまで頻発したらもう途中で投げてたかも(笑)。
PDFファイルの上限ページ数エラーというものがありました
こんな珍しいエラーも発生。
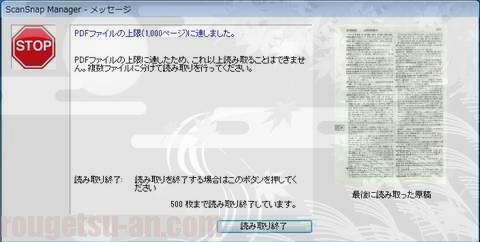
知らなかったけど、PDF出力の場合は一回1000ページ(両面読み取りだと500枚)まで行くと強制終了となる仕様でございました。文庫本・単行本なら大抵200ページ程度、ちょっと分厚い旅行ガイドなんかでも700ページ程度ですからね。滅多にお目にかからないハズ。
まあ、次のページから新たにスキャンを開始すれば良いだけなので特に問題ありませんが。
三時間以上かかってようやく終了
…ということで四苦八苦しながら悪戦苦闘し、なんと全て終わるまで約三時間も要してしまいました。ほとんど、重送のエラーページを探す手間に掛かった時間です。うーん、こんなんじゃ辞書ソフト買ってきた方が良いよね…(^^;)
外箱、表紙、他カラーページは別途プリンターのスキャナーで取り込み
最初に分解したビニールの表紙等は、別途平行して作業。プリンター複合機(キャノンMP560)に付属の、こちらのフラットベッドスキャナーで読み込んでみました。

まあ実用性だけ考えたら、自炊辞書に表紙なんか不要なんですけどね、この辺はお遊びでありますw

せっかくなので外箱も綺麗にカットしてスキャン。あくまで気分的なモンですがw
あまりナンも考えずに適当にスキャンし、あとで画像加工します。
フリーソフトのJ-timを使ってトリミングとサイズを調整。特にサイズ(画質)については、平行してScanSnapで読み込んでいるメインページ(辞書の中身)の縦横画素数に合わせておきます。これを合わせておかないと、実際にAcrobat Readerで見開き閲覧した際に、右のページはやたらデカイけど左側は豆粒、みたいな珍現象が起きますので注意。
こんな感じで、外箱、表紙、表紙の裏側、冒頭数ページと最後の方のカラーページ、などなど。全てJPEGデータで用意しておきます。後でメインページのPDFファイルと結合する時に、JPEGの方が楽に位置合わせできるので。
以上でスキャン作業自体は終了です。
てな訳でScanSnapさんはここで御役御免。この先はAcrobatでの作業となります。
スキャンしたデータを結合し、一つのPDFファイルにまとめる
ということで、PDF文書管理作成ソフトのAdebe Acrobatの登場です。
我が家のAcrobatはScanSnapS1500に同梱されてたヤツ。単品で買うと結構それなりなお値段ですので、スキャナーにバンドルされてるとありがたいですよね。バージョンはちょっと古い『9』ですが、それ以降のバージョンでも、基本的な使い方はそれほど変わらない筈です。なので、以下参考にされる際は、ご自身のお手元のAcrobatに照らし合わせてご確認ください。
尚、当然ですが、無料頒布されてる『Acrobat Reader』では編集作業は出来ません。分かってると思うけど念の為。
では参りましょう。
ScanSnapでスキャンして出来上がったPDFファイル(3個)と、先ほどの表紙や外箱などのJPEGファイル(10個)を同じフォルダにまとめます。
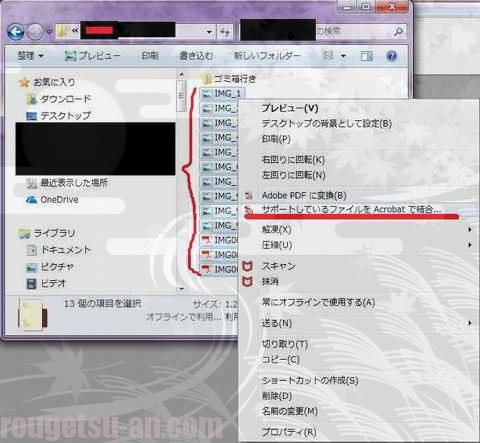
結合する13個のファイルを選択し、右クリック⇒「サポートしているファイルをAcrobatで結合…」を実行します。尚、繰り返しになりますが、Acrobatを持ってない方は、当然、右クリックしても何も出て来ませんからね。良いですね?
ダイヤログボックスが出てきますので、ページ順にファイルを入れ替えて並べなおします。
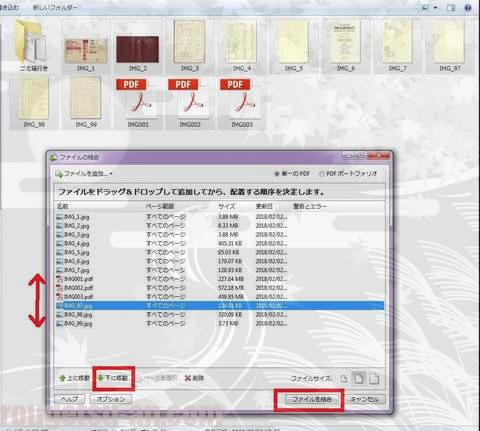
操作は直感的に出来ます。対象のファイルを選択して、下のコマンド「上に移動」「下に移動」するだけ。「最初に外箱⇒ビニール表紙⇒冒頭のカラー数ページ⇒辞書本文(PDFファイル)⇒最後カラーページ」というような順番にしました。
で、OKならば右下の「ファイルの結合」をクリックしてGo!! すると…
数十秒で結合完了し、新しいPDFファイルが作成されます。ファイル名を入力して保存すると…
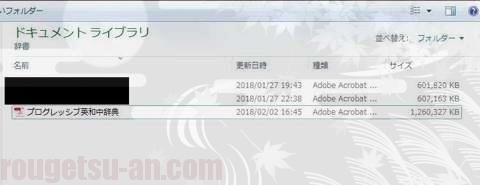
出来ました。ファイル名はそのまま「プログレッシブ英和中辞典」としてみました。しかし…サイズを見てビックリ(笑)。1.3GBもあります。ちょっとした長編の動画並ですな。さすがは辞書、恐るべし。こんな巨大なファイル、短時間で全文検索できるのだろうか(^^;)
ファイルサイズに関しては、この後のOCR行程で、「かなり賢い」Acrobatちゃんが併せ技によって結構劇的にデータ圧縮してくれます。なのでもうちょっとマシになるでしょう。
AcrobatでOCR処理をかける(同時にデータ圧縮もやってくれる)
いよいよ最後の行程です。いやあ長かったわ(涙)。
ここまでの状態で、一応e-book(e-dictionary)としては完成しとります。このまま英語の授業の予習復習に使うことも十分可能ですが、最後にOCR(光学式文字読取)処理をしてみましょう。上手く行けば、調べたい単語が説明文も含めて一発全文検索可能!! …になるハズなんですけどね。果たしてどうなりますことやら。
Acrobat9でのOCRは操作は簡単、ただし時間が…(^^;)
まずはただいま作成した上記のPDFファイル「プログレッシブ英和中辞典」をアクロバット9で開きます。辞書そのものの出来栄えもそれっぽくていい感じでしょ?
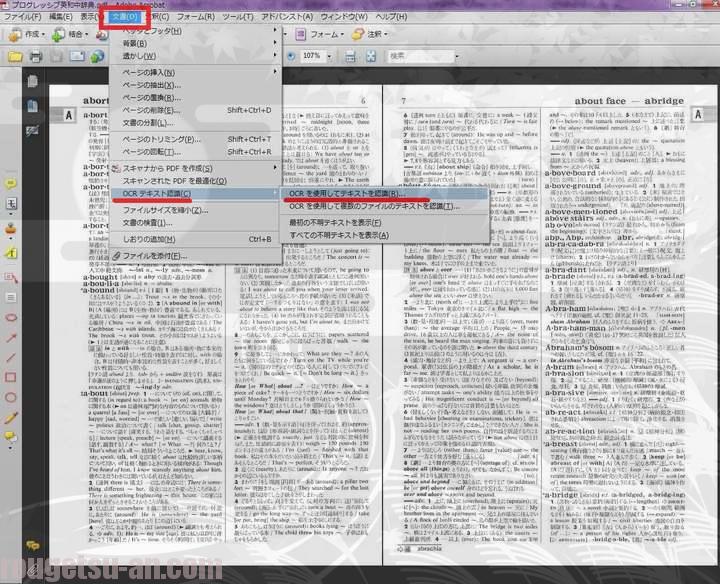
メニューから「文書」⇒プルダウンメニュー「OCRテキスト認識」⇒「OCRを使用してテキストを認識」と辿ります。
テキスト認識の設定ダイヤログです。
細かな設定はデータ量と画質の兼ね合いで個人の好みによりますが、私は基本的に「ダウンサンプリング:最低(600dpi)」でOCRをかけています。
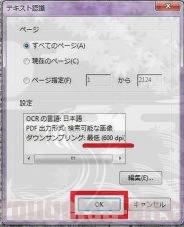
OKをクリックすると、OCR処理が始まります。
…やはり流石に長かったw
文庫本や単行本一冊とかだと10分程度ですけどね、さすがにこんな文字ばっかり2000ページもあると、正味三時間かかりました。オソロシス。まあ放っとくだけなので、エラーだらけだったスキャンに比べれば全然マシですが。
出来上がったのがこちら。
途中でエラーが数回出たので都度スキップしてしまいました。なので厳密に言うとOCRの網から漏れてるページが僅かにあります。
あと、前述の通り、AcrobatでOCR処理をすると、結構がんばってファイルサイズを圧縮してくれるのです。ちょっと写真が見難いですが、1.3GB⇒0.9GBと3割近く圧縮してくれました。助かります。
試しに、実際に全文検索してみた
早速試しにやってみました。
サクッとレスポンスの良い検索が出来れば大成功ですが…
『Acrobat 9』ではなく、閲覧で普段使いしてる、Acrobat Reader DCでやってみました。さきほどOCR処理⇒保存したファイルを開き、「Ctrl+F」で検索窓を開きます。試しに「dictionary」と入力、検索を開始すると…
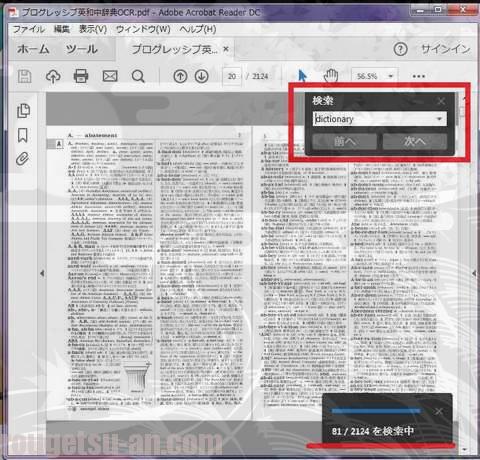
右下の作業窓をご覧ください。2124って…(^^;)
頑張ってくれてますが、ナカナカ進みません。全文検索するのに3分近く応答待ちでございました。やっぱりこれは厳しいかな~。これでも4コア8スレッドCPU&8GBRAMのワークステーション上なんですけどね。弱っちいノートPCやタブレット(ipadやkindle)だと、もうどうにもならないかも。
あとこの例に限った話ですが、説明文中の”dictionary”が案外多かったです。
当然前から順番に各駅停車します。電子辞書と違って見出し語に一発で連れて行ってくれないので、イラッとする方もいるかも。しかも、肝心の「見出し語のdictionary」は、なんとOCRに漏れてたようで、結局辿り付けないというオチでございました。アカンやん(^^;)
まあいずれ将来、プロセッサーの性能が上がったらもっと使えるようになるかな?
実験結果としては…ビミョーでございました。
おまけ Acrobatの「しおり機能」で目次を作ってみた
全文検索だけで強引にチカラワザで、という使い方はちょっと無理っぽいので、せめてABC順の索引というか目次を作っておくことにしました。そうすりゃ普通の辞書引く感覚で使えるハズですしね。
ということでAcrobatの「しおり」機能を使います。
編集作業となりますので、再度『Acrobat 9』の方でPDFファイルを開きます。左側の縦棒「ナビゲーションパネル」の上から二番目のマーク「しおり」をクリックします。すると右側に作業窓がビローンと開きます。
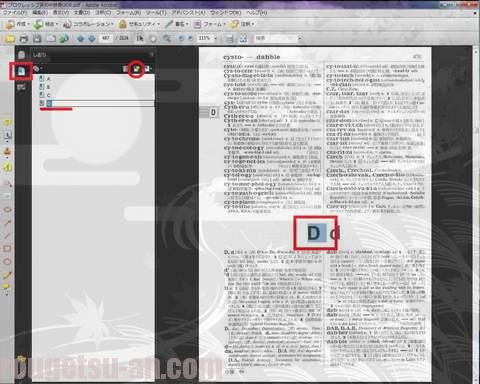
例えば上記のように『D』のページを開き、『D』をマウスカーソルでドラッグして選択します。で、左の作業窓の上の方、「新規しおり」のマークをクリックすると、下に『D』というしおりが追加されます。
この手順でA~Zまでをチャチャッと作成。出来上がりがこちら。
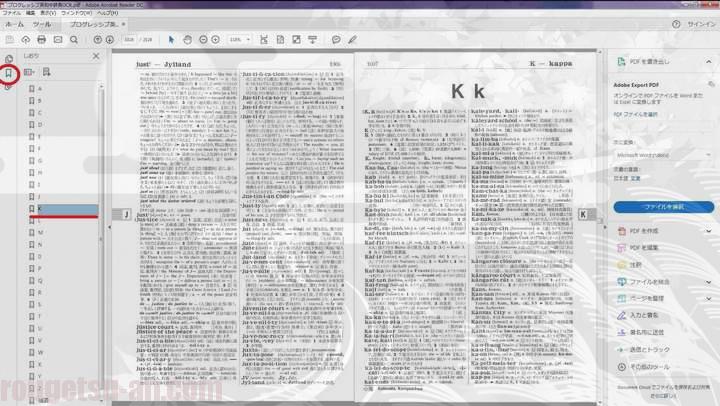
こんな感じですね。左側で、例えば『K』をクリックすると、Kのページの最初へ飛んでくれます。結構これだけでも便利かも。少なくとも手で辞書を引くよりは早いような気がしますね。案外使えそうかな?w

まとめ
ということで「英語辞書の自炊やってみた!!」でございました。
目論んでいた全文検索は果てなく玉砕でしたが、最終的に目次をつけたらソコソコ使えるんじゃね?というのが率直な感想でございます。
ただね、全文検索もページ量がもうちょっと少なければレスポンスはマシになるハズです。
例えば六法とかの条文とかね、サクッと単語から検索したいモノなんかは案外潜在的なニーズがあるかも。電話帳…は今時使う人はいないだろうけど、まあそんな類のモンですわ。あと資格取得の教本みたいなモノも意外と有用かもしれません。分からんところだけ逆引きで調べられるし、学習効果が高そうです。先生怒るだろうケド、ipadとかのタブレットに入れときゃ教科書も軽くなっていいよなw
ということで、最後に、気づいた点を簡単にまとめておきます。
メリットというか、案外イケルんじゃないの?という点は
- 案外普通の辞書のような感覚で使えそう。
- いわゆる電子辞書に比べるとやはり情報量が圧倒的に多い。
- しおりを使うと思ったより早く引ける。少なくとも手で「紙の辞書」を引くよりは早いのでは?
- 文字拡大できるので、年寄りには便利かも
逆にデメリットというか、これはアカンやろ、という点は
- 現行のPCのパワーだと、全文検索は遅くて実用に堪えない
- 電子辞書のように、見出し語にダイレクトで飛ぶことができない
- OCR処理がパーフェクトではないので、検索漏れが結構ありそう
- 何といっても、自炊時の重送エラーがメンドクサ過ぎる(爆笑)
…といったところでしょうか。やはり最後の点に尽きるかと。
ちょっと気軽にまたやろうかな、という気には…ナカナカなりませぬ(^^;)
あの薄い紙がね~。コツみたいなものも無いことはないんですがね、左右のサイズをかなり「精密」の揃えると重なりにくいようですが…まあでも裁断も手作業ですからね~。
冒頭申し上げた通り、あくまで興味本位のネタ記事ですのでご容赦くださいませ。
一応、自炊作業の基本行程は他の本・書籍(雑誌、漫画、コミック単行本etc.)でも応用可能かと思います。ドキュメントスキャナー導入をご検討中の方は、ご活用いただければ嬉しいです。ハッキリ言って、普通は重送エラーでこんなに苦労しませんw ご安心を。
(2018.3.14追記更新)ほぼノートラブルで(重送を回避して)スキャンする方法を発見しました!!
良い方法を見つけましたので簡単に追記しておきます。
やり方は簡単、フィーダーにセットする原稿を横向きに置くだけであります。
通常は変更をこう(↓)セットしますよね。

それを↓のように横向きに置くだけ。

これだけで、重送やジャムが劇的に減少しました。
完全にノートラブルとは言いませんが、辞書一冊1800ページ程度で、引っ掛かったのは両手まで行かない程度かな。普通の本を自炊する時とほぼ同じ、全くノーストレスでできました。

ナンとなーくそんな気はしてたのですが、裁断する時の微妙なサイズの違い(0.1mmとか)が良くないようです。縦に置くと、ロットの切替時に左右の幅がビミョーにズレて段差になるんでしょうね。んで、それが引き金で重送に。まあ普通の紙なら問題ないのでしょうが、辞書の薄い紙だとデリケート過ぎて巻き込んでしまうというしくみになっとるようで。
横置きにすれば、出版社というか印刷屋さんでカットした状態ですので全ページほぼ完璧に同サイズですのでね、ズレようがありません。これだけで大分違うのですね~。
ちょっとだけ注意が必要なのは、ページ端の折れ目、ドッグイヤーなどがある場合、ジャムることがありました。

まあでもトラブったのも極僅かでしたのしょうがないかな。
で、基本的に無問題でサクサクスキャンできるのですが、この方法だと一点だけ問題があります。
実際やってみれば分かると思いますが、出来上がったPDFファイルを見てみると…、横並びになっとるわけですね。なので最後にAcrobatで手直ししてやればOKです。
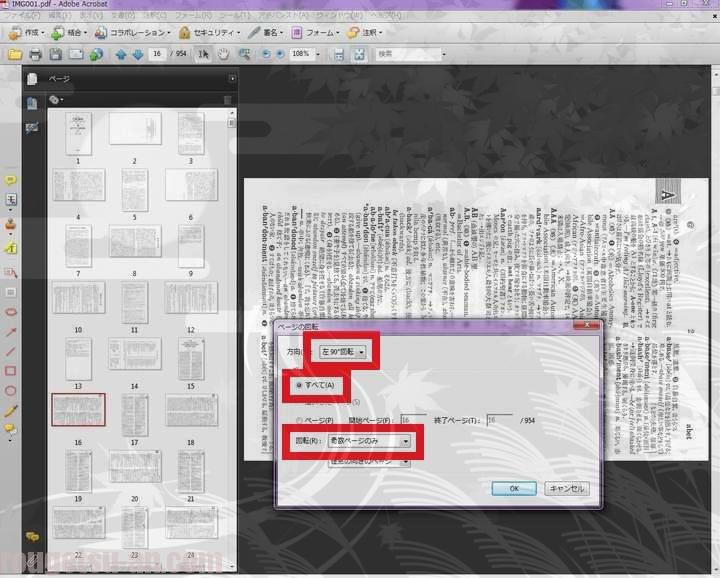
メニューの「文書」→「ページの回転」で、奇数ページは右90度回転、偶数ページは左90度回転、としてやればOKです。
以上、簡単ですが、要点のみ掻い摘んで。
最初にやった時よりも1/3-1/4程度の時間で済みました。あの苦労は何だったんだか(^^;)
本日も最後までお付き合い下さり、ありがとうございました。
富士通公式通販(WEB MART)のスキャンスナップのページはこちら
⇒『富士通パソコン通販 カラーイメージスキャナScanSnap 』
こちらもどうぞ♪
⇒『レンタルもおすすめ♪ヤフオク購入のScanSnapS1500で文書電子化&自炊が爆速に!!』 オススメ
⇒『卒業アルバム捨てる前に自炊電子データ化してみた』
⇒『Scansnap付属ソフトが秀逸♪名刺の自炊&デジタルデータ化やってみた』
⇒『年賀状を捨てる!!スキャン⇒パソコンでデジタルデータ保存』
⇒『安くて在庫豊富なネット通販「駿河屋」で古本購入してみた』
⇒『証券会社の書類をシュレッダーで大量処分』
⇒『故障シュレッダー試しに分解してみた&コクヨSilent-Duoが予想外に凄かった件』 オススメ
⇒『プリンターインク代を限りなくタダにする方法』
⇒『ワンクリック??で簡単♪AcrobatでXPS⇒PDF電子文書ファイル変換』
⇒『Word無料テンプレートで簡単 プリンターで印刷する喪中はがき』






コメント